ActiveSpaces
DataSpaces framework addresses data-intensive application workflows, which typically transform data they manage, and often reduce it before the data can be processed by consumer applications or services. For example, code-coupled application may only require subsets of data that are sorted and processed.
An initial solution we have explored consisted in embedding pre-defined data transformation operations in the staging area [3] to better utilize the CPU resources and transform the data before it is shipped to the consumer. This approach requires a priori knowledge of the processing, as well as the data structures and data representation.
ActiveSpaces is a data management framework that explores an alternate paradigm, it allows the application developers to programmatically define data-processing routines and dynamically deploy and execute them in the staging area at runtime rather that moving the data to the processing codes. ActiveSpaces builds on the concept of a staging area, and specifically on the DataSpaces[2] framework, which overlays the abstraction of an associative, virtual shared space on the staging area. Applications, which may run on remote and heterogeneous systems, can insert and retrieve data objects at runtime using semantically meaningful descriptors (e.g., geometric regions in a discretized application domain).
The ActiveSpaces framework provides (1) programming support for defining the data processing routines, called data kernels, to be deployed and executed on the staging area, and (2) run-time mechanisms for transporting the binary codes associated with these data kernels to the staging area and executing them in parallel on the staging nodes. The programming abstractions allow an application developer to define and implement the data kernels using all constructs of the native programming language ( e.g., C). The run-time mechanism enables code offloading and remote execution at the data source for HPC applications.
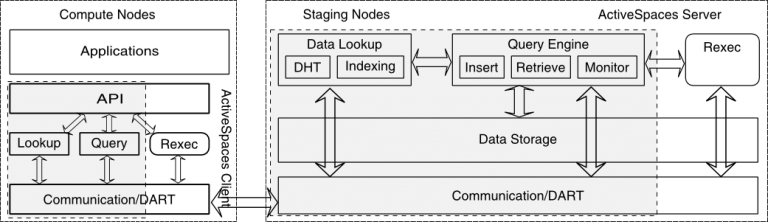
The ActiveSpaces architecture contains two main components an ActiveSpaces server and an ActiveSpaces client component. The ActiveSpaces server is a stand-alone component, which runs on the staging area and provides data services to user applications. The ActiveSpaces client integrates with user applications and runs on the computing nodes. These components implement the programming API which is exposed at the application level, and the run-time system, which executes the user-defined data kernels. ActiveSpaces extends the DataSpaces framework and implements new services to apply transformations to the data on the space or to the results of a data request. These services are provided by the run-time execution system (Rexec.)
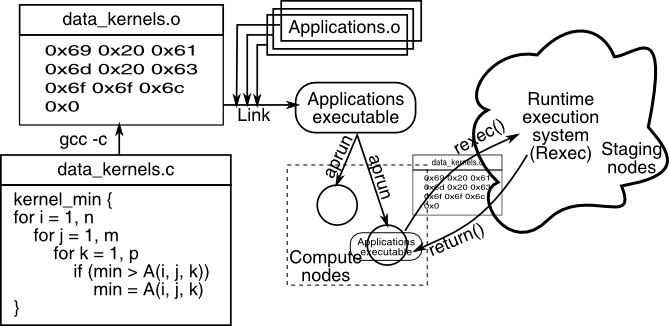
Data kernels are implemented within an application and have direct knowledge of the structure of the data used in the application. Once deployed on the space, these kernels can access the data directly and manipulate it without additional support from the space, such as parameter marshalling or data decoding. After executing a data kernel, the Rexec layer from the server component returns the results back to the application.
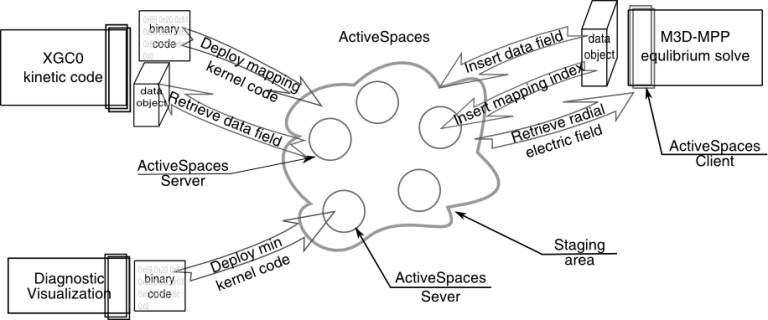
Multiple applications collaborating at runtime can insert data in the space, and can retrieve raw or pre-processed data of interest using the data kernels processing routines. ActiveSpaces can reduce the amount of data that needs to be transferred over the network for data reduction operations. It can also reduce an application’s computation time by offloading computations, such as interpolation, redistribution, reformatting, etc., which can be asynchronously executed in parallel on the staging area nodes. ActiveSpaces offers some benefits even in more constrained cases where execution of the data kernels is synchronous, because it can better exploit data locality within the staging nodes, because the number of nodes hosting the staging area is much smaller than the number of nodes running the application.
Autonomic Data Streaming and In-Transit Processing
Emerging enterprise/Grid applications consist of complex workflows, which are composed of interacting components/services that are separated in space and time and execute in widely distributed environments. Couplings and interactions between components/services in these application are varied, data intensive and time critical. As a results, high-through, low latency data acquisition, data streaming and in-transit data manipulation is critical.
The goal of this project is to develop and deploy an autonomic data management services that support high throughput, low latency data streaming and in-transit data manipulation. Key attributes/requirements of the service include: (1) support for high-throughput, low-latency data transfers to enable near real-time access to the data, (2) ability to stream data over wide area networks with shared resource and varying loads, and be able to maintain desired QoS, (3) minimal performance overheads on the application, (4) adaptations to address dynamic application, system, and network states, (5) proactive control to prevent loss of data, and (6) effective management of in-transit processing while satisfying the above requirements.
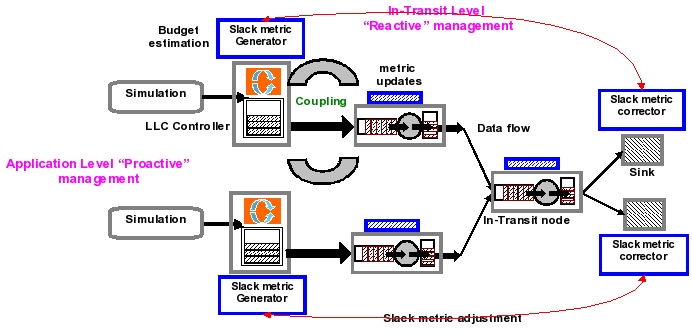
The autonomic services address end-to-end QoS requirements are addressed at two levels, which cooperate to address overall application constraints and QoS requirements. The QoS management strategy at the application end-points combines model-based limited look-ahead controllers (LLC) and policy-based managers with adaptive multi-threaded buffer management. The application-level data streaming service consists of a service manager and an LLC controller. The QoS manager monitors state and execution context, collects and reports runtime information, and enforces adaptation actions determined by its controller. In-transit data processing is achieved using a dynamic overlay of available resources in the data path between the source and the destination (e.g., workstations or small to medium clusters, etc.) with heterogeneous capabilities and loads. Note that these nodes may be shared across multiple applications flows. The goal of in-transit processing is to opportunistically process as much data as possible before the data reaches the sink, while ensuring that end-to-end timing constraints are satisfied. The combined constraints are captured using a slack metric, which bounds the time available for data processing and transmission, such that the data reaches the sink in a timely manner. The in-transit nodes then use this slack metric to appropriately select in-transit resources from the dynamic overlay so as to maximize the data that is processed in-transit and consequently the quality of data reaching the destination.
Experiments with end-to-end cooperative data streaming demonstrated that adaptive processing using the autonomic in-transit data processing service during congestions decreases the average idle time per data block from 25% to 1%, thereby increasing utilization at critical times. Furthermore, coupling end-point and in-transit management during congestion reduces average buffer occupancy at in-transit nodes from 80% to 60.8%, thereby reducing load and potential data loss, and increasing data quality at the destination. Ongoing work is focused on incorporating learning models for proactive management, and virtualization at in-transit nodes to improve utilization.